

Loss Functions - Training a neural network is an optimization problem. The goal is to find parameters that minimize this loss function and increase the model’s performance as a consequence.
So, training a neural network means finding the weights that minimize our loss function. This means that we need to know what loss functions are to make sure to use the right one based on the neural network we are training to solve a particular problem.
We will learn what loss functions are, what type of loss functions to use for a given problem, and how they impact the output of the neural network.
Let’s begin.
Overview
Loss Functions
What is a Loss Function?
Loss functions, also known as error functions , indicate how well the model is performing on the training data, allowing for the updating of weights towards reducing the loss, thereby enhancing the neural network’s performance.
In other words, the loss function acts as a guide for the learning process within a machine learning algorithm or a neural network.
It quantifies how well the model’s predictions match the actual target values during training.
Here are some terminology that you should be familiar with regarding calculating this.
- Loss Function: Applied to a single training example and measures the discrepancy between the predicted output and the true target.
- Cost Function: Refers to the aggregate (sum) of loss function over the entire dataset, including any regularization terms.
- Objective Function: This term is more general and refers to any function that an optimization algorithm aims to minimize or maximize. It encapsulates the overall goal of the optimization problem, whether it’s minimizing prediction error or maximizing accuracy.
Let’s dive deeper into how we can calculate the loss function.
How Do Loss Functions Work?
The figure below summarizes how loss functions work.
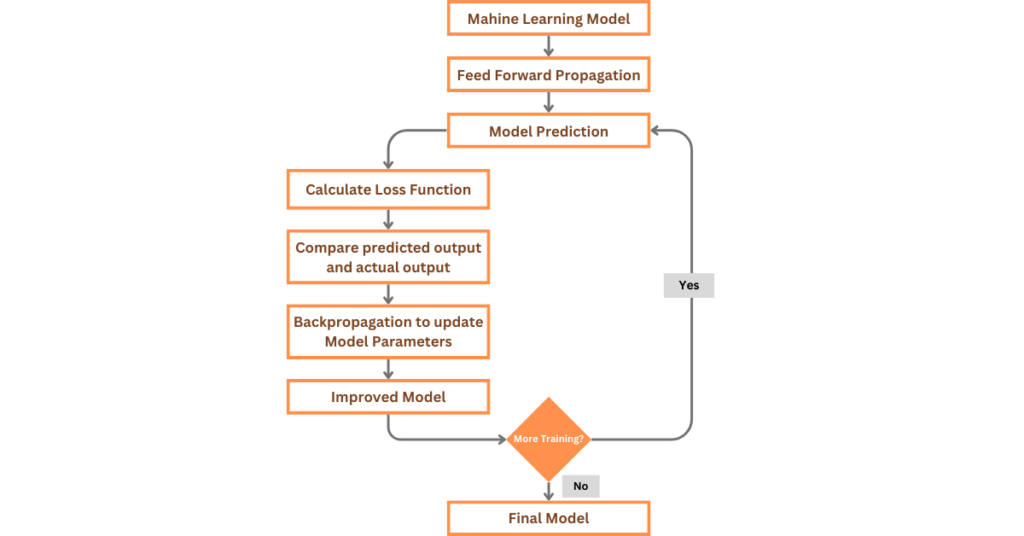
Here’s how loss functions typically work during the training process:
- Initialization: We start by initializing the model’s parameters randomly or with some predefined values.
- Forward Pass: We pass the input data through the model to obtain predictions
- Loss Function: We use this to calculate the difference between the predicted output and the actual target value for training samples. Helps us to measure how well the model is performing on training data
- Backpropagation: We use an optimization algorithm to adjust the model’s parameters in a way that minimizes the loss function. This is done by computing the gradient of the loss function with respect to each parameter using a technique called backpropagation.
- Parameter Update: We update the model’s parameter (i.e., weight) in the opposite direction to the gradient, scaled by a learning rate.
- Iteration: The process is repeated from doing forward passes to updating the parameter to improve the model’s performance gradually.
We pass the input data through the model to obtain predictions
Which Loss Functions To Use for Regression and Classification
Loss functions can be categorized based on the machine learning task.
Loss Functions for Regression
For a regression problem, where the goal is to predict continuous valued variables, we can use:
- Mean Squared Error (MSE)
- Mean Absolute Error (MAE)
Mean Squared Error (MSE) / L2 Loss
MSE is the squared difference between the predicted output and the actual output. It penalizes larger errors more heavily due to the squaring operation making it sensitive to outliers. This makes it more useful in scenarios where large errors should be minimized. Here’s how you can calculate MSE:
MSE = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2where y is the actual target value and \hat{y} is the predicted value.
Here’s an example where we have the data points and we want to learn a function that generates similar data points.
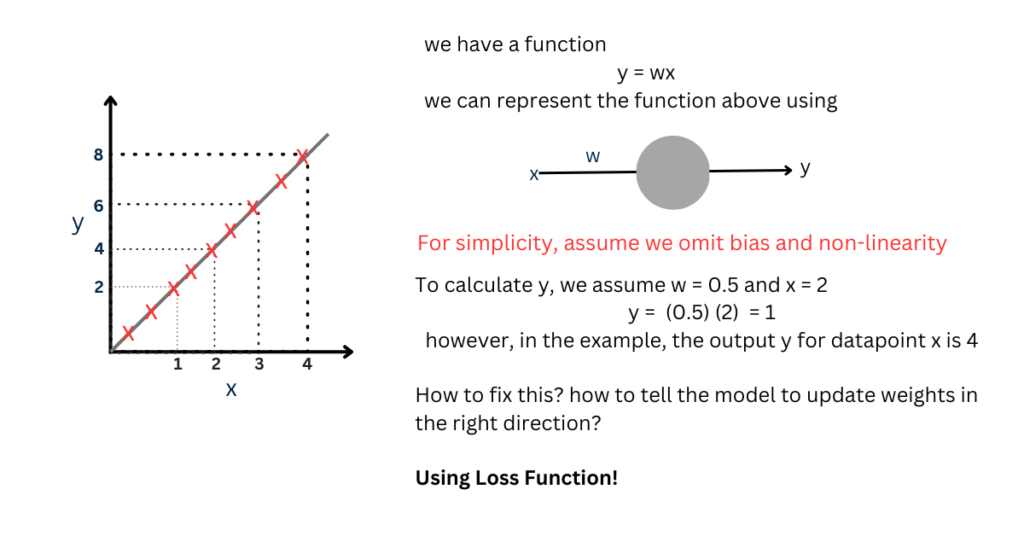
In the example above, we are using Mean Squared Error (MSE) to calculate the loss.
Once the loss function is calculated, we can calculate the derivative of weight w.r.t. loss (error) calculated and use it to define an update rule to update the weights to decrease the loss.
Here’s a post to help you understand how weights (parameters) of neural network are updated to train the neural network:
Mean Absolute Error / L1 Loss
Another loss function for regression problems (calculating continuous variables) is the Mean Absolute Error which calculates the absolute difference between the predicted and the actual output.
Unlike MSE which takes the squared differences, MAE treats all errors with equal weights regardless of their magnitude. Here’s how you can calculate it:
MAE = \frac{1}{n} \sum_{i=1}^{n} |y_i - \hat{y}_i|where n is the number of training samples, y is the actual target value and \hat{y} is the predicted value.
MAE is less sensitive to outliers compared to MSE. This property makes MAE more robust in the presence of data points with large errors thus providing more stable and reliable performance in the presence of outliers.
Loss Functions for Classification
For a classification problem, such as where the goal is to categorize input data into discrete classes or labels, we can train a model using the entropy loss function.
Cross Entropy
It is the measure of similarity between actual and predicted probability distribution of classes, here’s its mathematical form:
H (p,q) = - \sum_{i=1} p_{i} log q_{i}However, it should be kept in mind that this is not a similarity metric because it is not symmetric:
H(p,q) \neq H(q,p)So how do we get the probability distribution for classification problems? Let’s consider an example of a neural network for digit classification for this purpose:
Based on the classification problem, you can use different loss functions:
- Single Label Binary Classification: Binary Cross-Entropy (Log Loss)
- Multi-Label Multi-Class Classification: Categorical Cross-Entropy
Single Label Binary Classification
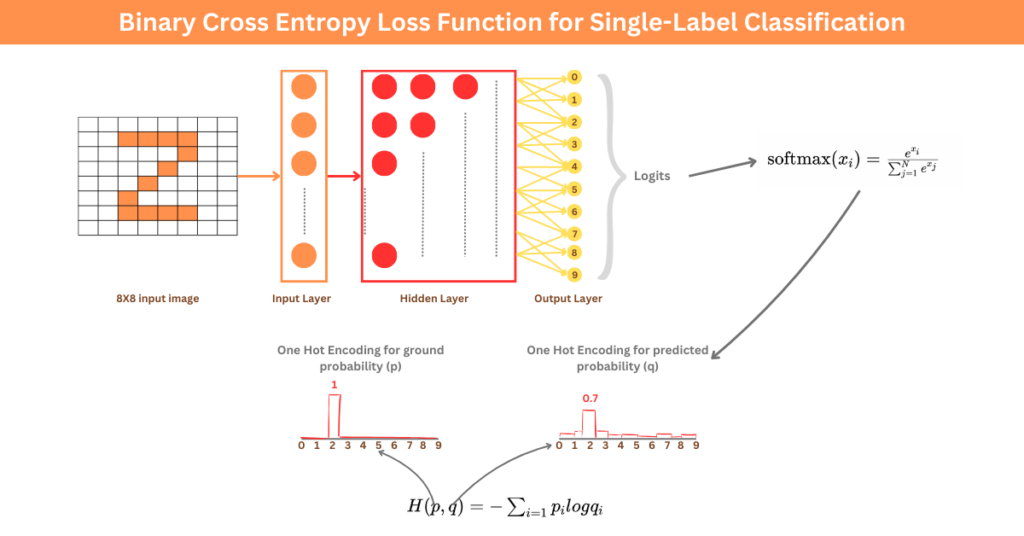
To understand this concept, let’s take an example of a digit classification problem, where the goal is to classify digits into multiple classes, each representing a distinct digit from “0” to “9”. Each digit is considered as a separate class.
We can use one-hot encoding to represent categorical variables as binary vectors. In this, each category is represented by a binary vector with element 1 (indicating the presence of that category), and all other elements are set to 0.
To get the predicted outputs, we pass the output variables (called logits) through soft probability functions like softmax which squashes the outputs to a range of [0,1] that sums up to 1 .
Once we have the predicted outputs and ground truth, we can calculate categorical cross-entropy.
Here’s a figure that summarizes multi-class digit classification.
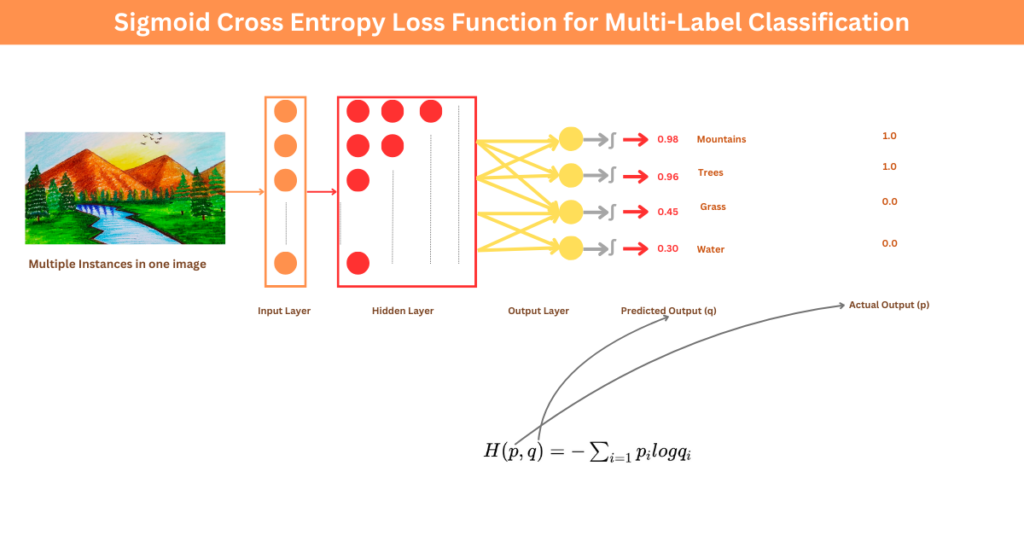
Multi-Label Multi-Class Classification Problem
For multi-label classification, where each instance belongs to multiple classes simultaneously, we need to:
Adjust the Output Layer: The neural network will have multiple nodes, each corresponding to a different class or label. Unlike single-label Classification (multi-class classification) in which we can use Softmax for exclusive classification, we pass the logits through separate sigmoid functions to handle scenarios where each instance can belong to multiple classes.
Next, we calculate the binary cross-entropy loss.
Summary
- Loss functions are crucial in training neural networks, quantifying the disparity between model predictions and actual targets.
- Key concepts such as loss functions, cost functions, and objective functions are defined and differentiated.
- The post provides a detailed overview of how loss functions work in the training process, including initialization, forward pass, loss calculation, backpropagation, and parameter update.
- Different types of loss functions for regression and classification tasks are explored, including Mean Squared Error (MSE), Mean Absolute Error (MAE), and Cross Entropy.
We’ve talked about some basic loss functions for classifying and predicting with neural networks. But don’t forget, there’s a whole bunch more out there to try!
And if none of those suit your needs, you can always whip up your very own custom loss function.
So, go ahead, get creative, and see what works best for your problem!
Further Reading
If you found this post useful, you might also want to read these:
- Understanding Optimization Algorithms In Deep Learning
- How to Train a Neural Network with Multiple Parameters
- How to Choose the Best Activation Functions for Hidden Layers and Output Layers in Deep Learning
Related Articles
- Loss Functions for Neural Networks for Image Processing
- The Real-World-Weight Cross-Entropy Loss Function: Modeling the Costs of Mislabeling

