

Activation functions have been an integral part of neural networks since their inception. These functions enable neural networks to learn and represent relationships in data. Without activation functions, neural networks would lose their expressive power, struggle to learn effectively and be limited in tackling real-world problems. In this post, you will learn what an activation function is, why we use it in neural networks, and explore how it helps in learning linear and non-linear decision boundaries.
Before we dive in, it would be better if you get comfortable with the concept of Neural Networks.
Let’s begin.
Overview
In this post, you will learn:
- What is an activation, and why do we use them?
- Linear activation function with example
- Non-linear activation Functions with example
1- What is an Activation Function and Why Use Them?
An activation function, sometimes called a ‘transfer function’ or ‘squashing function‘ defines how the weighted sum of input is transformed into an output from nodes in a layer within a network.
The selection of activation functions affects both the capability and performance of a neural network. Technically, the activation function operates within or after the internal processing of each node in a network. Also, networks are designed to use the same activation function for all nodes in a layer.
i. Layers in a Neural Network
Neural Networks commonly comprise three types of layers:
- Input Layers: These layers receive raw input data.
- Hidden Layers: Serving as intermediaries, hidden layers receive input from one layer and transmit output to another layer within the network.
- Output Layers: These layers are responsible for making predictions based on the processed data.
It is worth noting that all hidden layers typically use the same activation function. However, the choice of activation function in the output layer is dependent upon the type of prediction required by the model.
ii. What is “Differentiability” in Activation Functions?
One more thing about activation functions is that it needs to be ‘differentiable‘. Here’s a simple example to understand this:
Imagine you’re teaching a robot about how to make pancakes. The robot needs to learn from its mistakes to improve its pancake-making skills. To do this, you would use backpropagation, an algorithm that will give feedback to the robot after each pancake it makes.
Now, activation functions are special tools that the robot uses to adjust how much it learns from each mistake. We want these tools to be smooth and continuous, like a gentle slope, so the robot can make adjustments to get better at making pancakes.
Why does it need to be smooth and continuous? Well, imagine if the tool had sharp edges or sudden jumps, It would be like trying to climb a mountain with cliffs instead of a smooth slope. The robot wouldn’t know how to make these small adjustments and it might stuck or even worse, make big mistakes.
So, activation functions need to be “differentiable” which means that we can calculate how steep the slope is at any point. This helps the robot know which direction to adjust its pancake-making skills after each attempt. If the slope is steep, it means the robot needs to make a big change. If it’s gentle, it can make small adjustments.
Simply put, activation functions help the robot learn from its mistakes by providing smooth and continuous guidance, just like a gentle slope helps you climb a hill. Being differentiable means we can calculate how steep the slope is, so the robot knows how much to adjust its skills.
There are many activation functions used in neural networks, let’s have a look at the variants of activations and see how these are used for each type of layer.
2- Variants of Activation Functions
i. Linear Activation Functions:
Now is the time to learn some basics of activation functions. Up until now, we have been working with linear activation functions. Each of these neurons takes a weighted sum of their inputs. But, isn’t a weighted sum of linear functions also a linear function? Let’s understand this by taking a slice from this network and see what happens:
In this example of a single slice neural network, the input x gets multiplied by weights w_0, w_1, w_2, w_3 and we get our output. Here is the mathematical equation for this:
y = xw_0w_1w_2w_3 = xw_c
We can represent this function as a single neuron. This is because when we don’t introduce non-linearities between neurons, the entire network would collapse into a single linear function. This limits the model’s ability to learn complex patterns and relationships between data.
Introducing non-linear functions allows neural networks to model more complex relationships in data and helps the model to learn non-linear decision boundaries.
Let’s run a simulation on Tensorflow playground to see how Linear activation function performs on linearly separable data and complex patterns.
In this scenario, we have linearly separable data, where a simple linear activation function can successfully find a line that best fits the data. However, when the data is transformed into a Swiss roll-shaped manifold—a complex, nonlinear structure—the limitations of linear activation functions become apparent. In such cases, a linear activation function cannot capture the intricate curvature and complexity of the data, rendering the neural network incapable of accurately modeling the underlying patterns.
ii. Non-Linear Activation Function
Non-linear activation functions play a crucial role in artificial neural networks by introducing non-linearity into the network’s decision-making process. These functions allow neural networks to model complex relationships and learn from non-linear patterns in the data.
But how does it work?
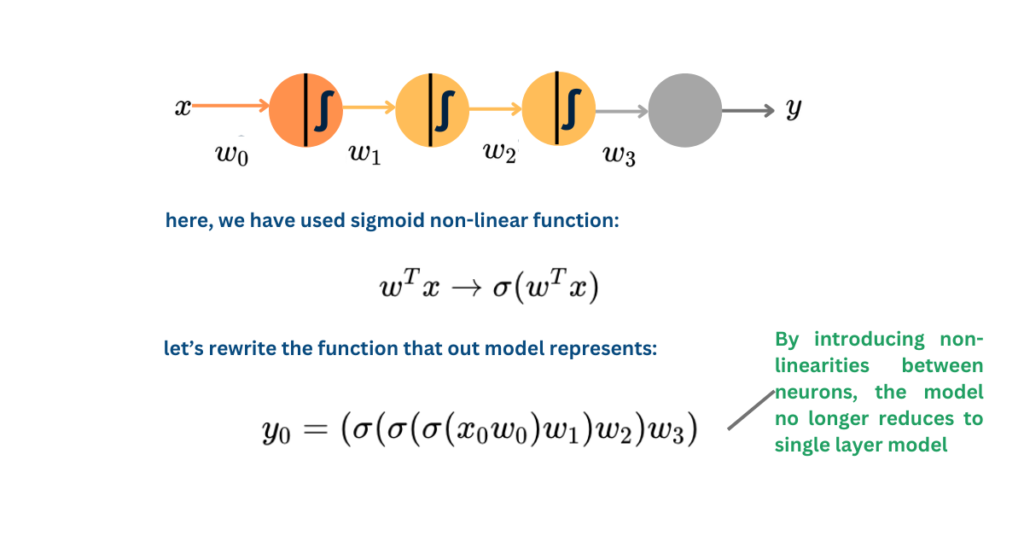
In the above example, the sigmoid non-linear activation function squashes the input between 0 and 1. When we use a non-linear activation function, we pass the output of a neuron through a non-linear function before we feed it to the next layer. Doing so introduces non-linearities in our network.
Now that we’re familiar with the concept of linear and non-linear activation functions, it’s finally time to see what types of activations can be used for each type of layer. Here’s a post that covers which activation functions you should choose for hidden layers and output layers:
Which Activation Functions Are Best for Hidden and Output Layers in Deep Learning
Summary
- Linear activation functions result in linear decision boundaries, limiting the network’s ability to capture complex patterns in data.
- Activation functions can be visualized using an open-source tool: Tensorflow playground.
- Introducing non-linear activation functions allows neural networks to model more complex relationships and learn non-linear decision boundaries.

