

The exploding gradients occur in a situation opposite to the vanishing gradient problem. Instead of gradients becoming vanishingly small, they become extremely large during training.
This makes your model unstable and unable to learn from your training data.
In this post, we will understand the problem of exploding gradients in deep artificial neural networks.
Let’s begin
Overview
In this post, we will cover:
- What exploding gradient is and its causes.
- How do we know if the model has an exploding gradient problem?
- How to fix the exploding gradient problem?
1 - What are Exploding Gradients?
The exploding gradient problem happens when the gradients in a neural network become so large that it messes up the training process.
During backpropagation, the gradient of the loss function w.r.t. network’s parameters (such as weights and biases) becomes extremely large. When the gradient becomes too large, it can lead to numerical instability and difficulties in training the neural network effectively. Essentially, the updates to the parameter become so large that they cause the network’s parameter to “explode” meaning they grow uncontrollably.
This can result in unpredictable behavior during training, making it difficult for the network to converge to a solution and hindering its ability to learn meaningful patterns in the data.
2 - Understanding Exploding Gradients Through Example
Let’s take the same example that we looked at for vanishing gradient problem, and see what exploding gradients would look like:
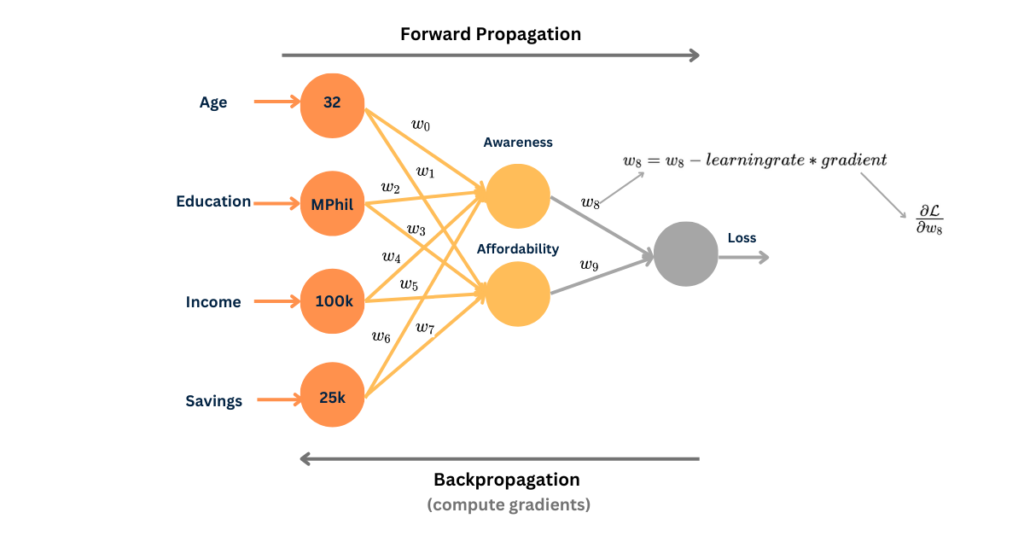
For example, if we try to calculate the gradient of loss w.r.t. weight w_1
\frac{\partial \mathcal{L}}{\partial w_1} = \frac{\partial \mathcal{L}}{\partial Awareness} \frac{\partial \mathcal{Awareness}}{\partial w_1}gradient = d1 * d2,
where d1 = \frac{\partial \mathcal{L}}{\partial Awareness} and d2 is \frac{\partial \mathcal{Awareness}}{\partial w_1}
gradient = 100 * 400 = 4000As you can see, the resultant gradient is a bigger number causing the gradient to explode!
3 - How do You Know if the Model has Exploding Gradients?
Detecting the presence of exploding gradients in a neural network model typically involves monitoring the magnitude of gradients during training. Here are some signs that suggest the presence of exploding gradients:
- The model is unstable, meaning, the loss (or error) of your model fluctuates wildly during training.
- If you encounter NaN (Not a Number) or infinity values for loss during training.
- If your model’s performance metrics are not improving or are deteriorating during training.
- If the model’s parameters (weights and biases) are being updated with very large values.
- If you observe spikes or very high values in gradient plots.
- If you need to decrease the learning rate significantly during training to prevent instability.
3 - How to Fix Exploding Gradients?
To fix the exploding gradient problem, there are several strategies that you can implement. Here are some common techniques to address this issue:
i. Simplify Your Neural Network
You can reduce the depth to have fewer layers within the network. Also, while training the neural network, you can use a smaller batch size to resolve this issue.
ii. Gradient Clipping
Gradient clipping helps prevent gradients from becoming too large during training. It involves setting a threshold value for the gradients, and if the magnitude of any gradient exceeds this threshold, it is scaled down to match the threshold.
iii. Weight Regularization
Weight regularization techniques such as L1 and L2 regularization, add a penalty term to the loss function. It discourages the model from learning overly complex patterns. By penalizing large weights, regularization helps prevent the gradient from becoming too large during training.
iv. Batch Normalization
The batch normalization technique normalizes the activations of each layer in the network. This helps in stabilizing the distribution of inputs to each layer making it less likely for gradients to become too large. It can be applied before or after the activation function in each layer.
So, now we know what the exploding gradient problem is, how we know if our neural network has one, and how to fix it. Here are some resources if you wish to dig deeper:
Summary
- Exploding gradient problem occurs when gradients in neural networks become extremely large, leading to numerical instability.
- Signs of exploding gradients include unstable model behavior, fluctuating loss, encountering NaN or infinity values, spikes in gradient plots, and large parameter updates.
- To fix this problem, different strategies including simplifying the neural network architecture, batch normalization, and gradient clipping can be applied.

